
그렇다면 시간대별로 사람들이 가장 많이 타고 내리는 역은 어디일까?
24시간 전체에 대해 계산해보자. for loop를 사용하면 좋겠다. 또한 시간대별 데이터를 각각 저장할 리스트도 필요하다. 우리가 표현할 시간대는 24시간을 1시간 단위로 구부하였으므로 총 24개이다.
range함수를 사용한다면 range(24)로 쓸 수 있다. range함수는 0부터 시작하므로 0~23을 표현할 인덱스 j가 필요하다.
또한 승차 인원 값의 인덱스 i가 있다. i는 4부터 시작한다. 이때 i와 j를 비교해보자.
| for 반복무네 사용되는 변수 j와 인덱스 사이의 패턴 찾기 | ||
| 변수 j | 인덱스 i | 패턴 |
| 0 | 4 | i = j * 2 + 4 |
| 1 | 6 | |
| 2 | 8 | |
| ... | ... | |
| 23 | 50 | |
이 패턴을 바탕으로 다음과 같이 코드를 작성한다.
import csv
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data); next(data)
mx = [0] * 24 # 시간대별 최대 승차 인원 저장 리스트 초기화
mx_station = [''] * 24 # 시간대별 최대 승차 인원 역 이름 저장 리스트 초기화
for row in data:
row[4:] = map(lambda x : x.replace(',',''), row[4:])
row[4:] = map(int, row[4:])
for j in range(24):
i = row[j*2 + 4] # j와 인덱스 번호 사이의 관계식 이용
if i > mx[j]:
mx[j] = i
mx_station[j] = f'{row[3]} ({j+4}시)'
print(mx_station)
print(mx)
이제 이 데이터를 바탕으로 막대 그래프를 그려보자.
x축에는 시간대별 1위를 차지한 역의 이름을 90도 회전하여 표현한다.
import matplotlib.pyplot as plt
plt.rc('font', family='Malgun Gothic')
plt.bar(range(24), mx)
plt.xticks(range(24), mx_station, rotation=90)
plt.show()
실행 결과를 보니 1시간 단위로 시간대별 승차인원이 가장 많은 곳으로 신림역이 8번, 강남역이 11번 나온다. 24시간중 11시간이 수도권 전체 지하철역 중 강남역에 가장 많은 사람이 승차한다는 사실을 알 수 있다.
여기서 24시 이후로, 25시, 26시로 출력되는 것을 볼 수 있다. 이것은 새벽 1시, 2시를 의미한다. 이것을 1시, 2시로 바꾸기 위해서는 어떻게 해야할까.
mx_station[j] = f'{row[3]}({(j+4)%24}시)'이런 식으로 mod 연산자를 사용한다.
시간대별 하차 인원이 가장 많은 지역
import csv
import matplotlib.pyplot as plt
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data); next(data)
mx = [0] * 24 # 시간대별 최대 승차 인원 저장 리스트 초기화
mx_station = [''] * 24 # 시간대별 최대 승차 인원 역이름 저장 리스트 초기화
for row in data:
row[4:] = map(lambda x:x.replace(',',''), row[4:])
row[4:] = map(int, row[4:])
for j in range(24):
a = row[j*2 + 4] # j와 인덱스번호i 사이의 관계식 사용
if a > mx[j]:
mx[j] = a
mx_station[j] = f'{row[3]}({(j+4)%24}시)'
plt.rc('font', family='Malgun Gothic')
plt.bar(range(24), mx)
plt.xticks(range(24), mx_station, rotation=90)
plt.show()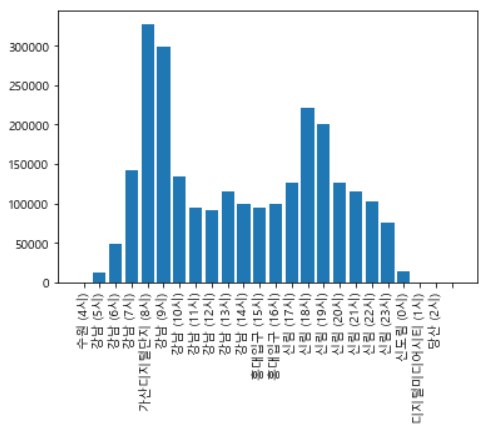
결과를 보면 출근시간에는 강남역이, 낮 시간에는 홍대입구역, 퇴근 시간에는 신림역이 출력된 것을 확인할 수 있다.
모든 지하철역에서 시간대별 승하차 인원을 모두 더해보자.
지금까지는 사람들이 가장 많이 타고 내리는 역이 어디인지, 그 시간대는 언제인지르 살펴보았다. 만약 모든 지하철역의 시간대별 승하차 인원을 모두 더하면 어떤 결과가 나올까?
1. 데이터를 읽어온다.
2. 모든 역에 대해 시간대별 승차 인원과 하차 인원을 누적해서 더한다.
3. 시간대별 승차, 하차 인원을 그래프로 표현한다.
1. 데이터 읽어오기.
24시간 데이터를 순서대로 저장하기 위해 리스트를 만든다. 승차 인원을 저장하는 s_in과 하차 인원을 저장하는 s_out 리스트를 생성한다.
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data); next(data)
s_in = [0] * 24
s_out = [0] * 242. 시간대별 승차, 하차 인원 누적하기
모든 역에 대해 시간대별 인원을 누적해서 더한다.
for row in data:
row[4:] = map(lambda x:x.replace(',',''), row[4:])
row[4:] = map(int, row[4:])
for i in range(24):
s_in[i] += row[4+i*2]
s_out[i] += row[5+i*2]3. 그래프로 표현하기
승차 인원 그래프와 하차 인원 그래프, 두 개의 그래프를 비교하기 위해 꺾은선 그래프로 그려준다. 제목과 범례도 추가해보자.
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data); next(data)
s_in = [0] * 24
s_out = [0] * 24
for row in data:
row[4:] = map(lambda x:x.replace(',',''), row[4:])
row[4:] = map(int, row[4:])
for i in range(24):
s_in[i] += row[4+i*2]
s_out[i] += row[5+i*2]
plt.rc('font', family='Malgun Gothic')
plt.title('지하철 시간대별 승하차 인원 추이')
plt.plot(s_in, label='승차')
plt.plot(s_out, label='하차')
plt.legend()
plt.xticks(range(24), range(4, 28))
plt.show()

결과를 보면 출근 시간대에는 승차인원이 7~8, 8~9시에 많고, 하차 인원은 8~9시가 많다. 퇴근 시간대는 승차가 18~19시에 많고, 하차는 18~19, 19~20시가 가장 많다.
좌측 상단에 1e7은 1 * 10^7을 의미한다. 따라서 현재 y축에 표시된 승하차 인원에 대한 단위가 천만 명이라는 것이다.
정리
본인이 출근하는 시간대는 비교적 지하철 이용 인원이 적은 편인지 아닌지 경험으로 알 수 있는 추측이 아닌, 데이터에 근거한 결과를 확인하라. 이러한 데이터 분석 결과들을 바탕으로 개인의 궁금증을 해결하는 것에서 그치지 않고, 다른 사람을 설득하는데 데이터에 근거한 논리를 펼친다면 더욱 다양한 각도에서 문제를 바라보는 힘을 기를 수 있다.
'PNU DSC > 파이썬 데이터 분석' 카테고리의 다른 글
| 04-2. 대중교통 공공데이터 - 지하철 시간대별 데이터 (0) | 2020.06.17 |
|---|---|
| 04-1. 대중교통 공공데이터 (0) | 2020.05.29 |
| 03-4. 인구 공공데이터 - 산점도 (0) | 2020.05.23 |
| 03-3. 인구 공공 데이터 - 파이차트 (0) | 2020.05.23 |
| 03-2. 인구 공공데이터2 (0) | 2020.05.15 |