
1. 출근 시간대 사람들이 가장 많이 타고 내리는 역은 어디인가.
2. 지하철 시간대별로 가장 많은 사람이 승하차 하는 역은 어디인가.
1. 지하철 시간대별 이용 현황 데이터 정제하기
교통카드 데이터 파일에서 지하철 시간대별 이용현황 시트를 선택한다.

해당 시트를 파일->다른 이름으로 저장 한 뒤에 subwaytime으로 정하고 파일 형식을 csv로 선택한 후 저장한다.
가장 우측에 있는 작업 일시 열을 삭제한다.
import csv
with open('subwaytime.csv') as f:
data = csv.reader(f)
for row in data:
print(row)
출력된 결과를 살펴보면 헤더(header)가 2개의 행으로 이루어져있다. 첫번째 행은 사용월, 호선명, 역 ID, 역이름 그리고 AM 4:00부터 다음날 AM 3:00까지의 시간이 1시간 단위로 구분되어 있다. 두번째 행은 공백 4개와 승차와 하차가 번갈아 나온다. 이 두 줄은 데이터 분석에 직접적인 필요가 없으므로 next() 함수로 제외시킨다.
그 이후의 각 행의 4번 인덱스부터 마지막까지의 데이터를 콤마(,)를 없애고 int(정수)로 바꾼다. map()함수를 이용한다.
row[4:] = map(lambda x:x.replace(',',''), row[4:]) # 콤마(,)를 없앤다.
row[4:] = map(int, row[4:]) # 정수로 바꾼다.
해당 코드를 이용해서 출력해보자.
import csv
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data)
next(data)
for row in data:
row[4:] = map(int, list(map(lambda x : x.replace(',',''), row[4:])))
print(row)
2. 출근 시간대 사람들이 가장 많이 타고 내리는 역은 어디일까

아침 7시의 승차 데이터의 위치를 확인하니 10번 인덱스에 저장되어 있다. 10번 인덱스의 데이터만 추출해서 리스트에 저장하고 출력해보자.
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data)
next(data)
result = []
for row in data:
row[4:] = map(int, list(map(lambda x : x.replace(',',''), row[4:])))
result.append(row[10])
print(len(result))
print(result)
이제 이 데이터를 막대그래프로 표현해보자.
import csv
import matplotlib.pyplot as plt
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data)
next(data)
result = []
for row in data:
row[4:] = map(int, list(map(lambda x : x.replace(',',''), row[4:])))
result.append(row[10])
plt.bar(range(len(result)), result)
plt.show()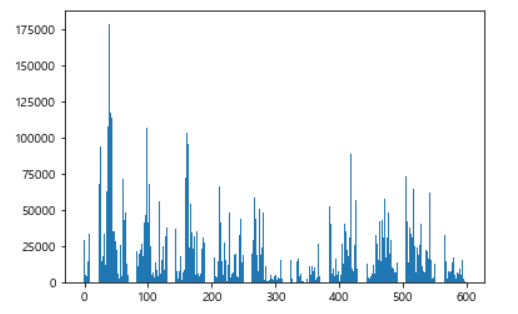
위의 그래프를 보면 데이터의 편차가 매우 크다는 사싱르 알 수 있다. 이번에는 데이터를 오름차순으로 정렬한 뒤에 그래프로 출력해보자.
import csv
import matplotlib.pyplot as plt
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data)
next(data)
result = []
for row in data:
row[4:] = map(int, list(map(lambda x : x.replace(',',''), row[4:])))
result.append(row[10])
result.sort() # 오름차순으로 정렬
plt.bar(range(len(result)), result)
plt.show()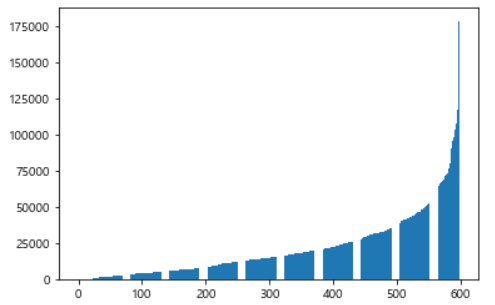
딱 한 역이 다른 역과는 엄청나게 큰 차이를 두고 1위를 하고 있다. 그러면 출근 시간대인 7~9시까지 승차 인원을 합쳐서 살펴보자. 7시 인덱스가 10이므로 10, 12, 14번 인덱스를 합쳐서 막대그래프로 표현하면 된다.
import csv
import matplotlib.pyplot as plt
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data)
next(data)
result = []
for row in data:
row[4:] = map(int, list(map(lambda x : x.replace(',',''), row[4:])))
result.append(sum(row[10:15:2]))
plt.bar(range(len(result)), result)
plt.show()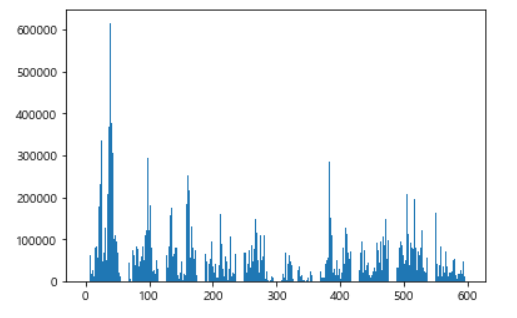
혼자 독보적으로 많은 역이 도대체 어디일까? 이 문제는 지금까지 많이 다뤄본 패턴인 '최대값 찾기'이다. 승차인원 최대값을 저장할 변수와 역의 정보를 저장할 변수를 생성한다. 그리고 7~9시 까지의 승차인원 합계의 최대값을 찾아서 출력한다.
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data); next(data)
mx = 0 # 최대값을 저장할 변수 초기화
mx_station = '' # 최대값을 갖는 역이름을 저장할 변수 초기화
for row in data: # 최대값 찾기
row[4:] = map(int, list(map(lambda x : x.replace(',',''), row[4:])))
if sum(row[10:15:2]) > mx:
mx = sum(row[10:15:2])
mx_station = row[3] + '(' + row[1] + ')'
print(mx_station, mx) 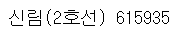
결과를 보면 2호선 신림역에서 출근시간대에 60만명 이상이 이동한다는 것을 알 수 있다. 코로나로 인한 팬데믹 상황인 것을 감안하면 굉장히 많은 인원이라는 것을 알 수 있다. 지금까지 '출근 시간대에 사람들이 가장 많이 타는 역은 어디일까?'를 데이터 분석을 통해서 알아보았다.
그러면 출근 시간대에 사람들이 가장 많이 내리는 역은 어디일까?
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data); next(data)
mx = 0
mx_station = ''
for row in data:
row[4:] = map(lambda x : x.replace(',',''), row[4:])
row[4:] = map(int, row[4:])
getoff = row[11:16:2] # 하차 인원 값 추출
if sum(getoff) > mx:
mx = sum(getoff)
mx_station = f'{row[3]}({row[1]})'
print(mx_station, mx)
3. 밤 11시에 사람들이 가장 많이 타는 역은 어디일까?
밤 11시는 23시 ~ 23시 59분 59초 사이를 말한다. 이 시간대에 사람들이 어떤 역에 탄다면 이 사람들은 이 시간에 왜 지하철에 탔으며 그 전까지는 무엇을 했을지 생각해보면 답을찾는 과정이 더 재밌을 것이다.
밤 11시의 데이터는 몇번 인덱스에 있을까?
| 승차 시각과 인덱스 사이의 패턴 찾기 | ||
| 승차시각(t) | 인덱스(i) | 패턴 |
| 4 | 4 | i = 4 + (t - 4) * 2 |
| 5 | 6 | |
| 6 | 8 | |
| 7 | 10 | |
| ... | ... | |
| 23 | ? | |
해당 패턴을 이용해서 시간 t를 input()으로 입력받도록 구현해보자.
특정 시작에 사람들이 가장 많이 타는 역을 찾는 코드
with open('subwaytime.csv') as f:
data = csv.reader(f)
next(data); next(data)
mx = 0
mx_station = ''
t = int(input('몇시의 승차 인원이 가장 많은 역인지 궁금한가요?'))
for row in data:
row[4:] = map(lambda x:x.replace(',',''), row[4:])
row[4:] = map(int, row[4:])
geton = row[2*t - 4] # 입력받은 시각의 승차 인원 추출 index = 4 + (t-4) * 2
if geton > mx: # 모든 데이터 탐색
mx = geton
mx_station = f'{row[3]}({row[1]})'
print(mx_station, mx) # 승차 인원이 가장 큰 역과 인원 출력 
정답은 강남역이었다. 밤 11시에 가장 많이 타는 이유는 늦게까지 야근을 했거나 친구들을 만나고 놀다가 집에 귀가하는 것이라고 미루어 짐작할 수 있다.
그렇다면 시간대별로 사람들이 가장 많이 타고 내리는 역은 어디일까?
'PNU DSC > 파이썬 데이터 분석' 카테고리의 다른 글
| 04-3. 대중교통 공공데이터 - 시간대별 승하차 (0) | 2020.07.04 |
|---|---|
| 04-1. 대중교통 공공데이터 (0) | 2020.05.29 |
| 03-4. 인구 공공데이터 - 산점도 (0) | 2020.05.23 |
| 03-3. 인구 공공 데이터 - 파이차트 (0) | 2020.05.23 |
| 03-2. 인구 공공데이터2 (0) | 2020.05.15 |