
해당 글은 [송석리, 이현아의 모두의 데이터분석 with 파이썬]을 공부하고 정리하기 위해서 작성한 글입니다.
1. 기온 데이터 분석
2. 부산의 기온 데이터 분석하기
3. 부산이 가장 더웠던 날 구하기
1. 기온 데이터 분석하기
# 공공데이터란 무엇인가?
어렵게 생각하지 말자. 모두를 위해 공개된 데이터이다. 그 중 우리가 첫번째로 다룰 데이터는 기온 데이터이다.
https://data.kma.go.kr/cmmn/main.do
기상자료개방포털
data.kma.go.kr


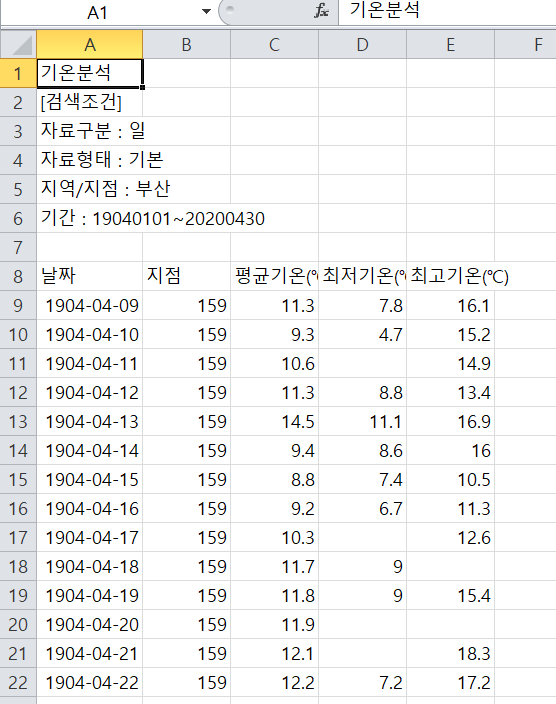
다운받은 csv파일을 확인하면 다음과 같다.
# CSV 파일이란 무엇인가
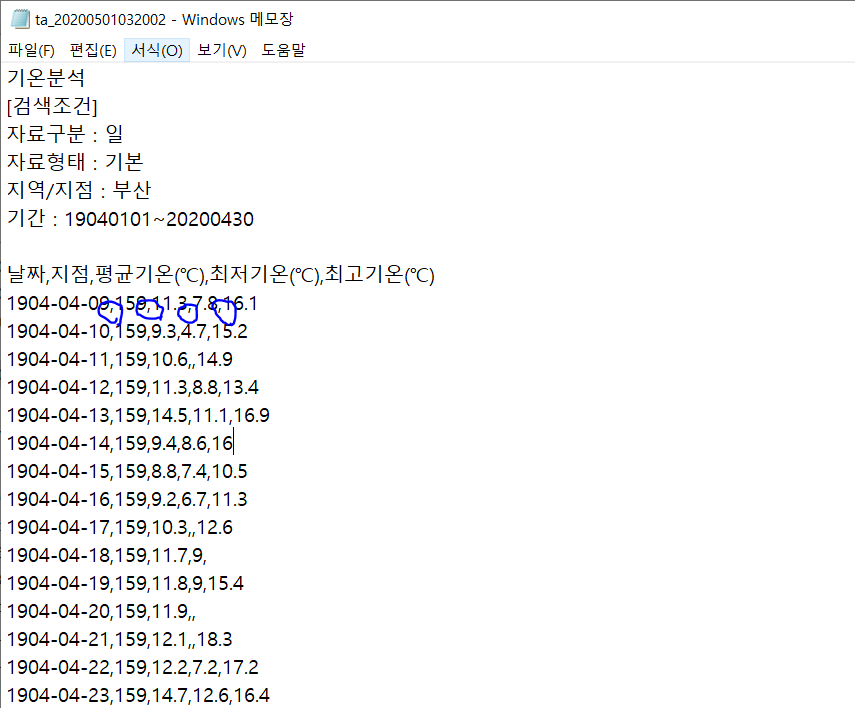
CSV는 'Comma Separated Values'의 약자로 각 데이터가 콤마(,)로 구분된 파일 형식이다. 해당 csv파일을 메모장으로 열면 확실하게 확인할 수 있다.
# 데이터 분석에 필요한 환경 만들기
아나콘다 공식 홈페이지로 가서 본인의 OS에 맞는 Anaconda를 설치한다.
https://www.anaconda.com/products/individual
Individual Edition | Anaconda
🐍 Open Source Anaconda Individual Edition is the world’s most popular Python distribution platform with over 20 million users worldwide. You can trust in our long-term commitment to supporting the Anaconda open-source ecosystem, the platform of choice for
www.anaconda.com

* 아나콘다(Anaconda) : 파이썬의 라이브러리 패키지이다. 파이썬도 여러가지 버전과 라이브러리가 있는데 이를 하나로 묶어 개발하기 편하게 한것이 아나콘다이다.
* 주피터 노트북(Jupyter Notebook) : 서버 클라이언트 어플케이션으로 웹에서 편집, 실행하는 기능을 지원한다. 파이썬 자체로는 실행 결과를 바로 볼 수 없지만, 주피터 노트북을 사용하면 웹브라우저를 통해 명령과 실행을 동시에 수행할 수 있습니다.
* 주의사항
1. 설치경로에 한글이름을 넣지마라
2. 두 체크박스를 반드시 체크하라.

3. 크롬을 기본 브라우저로 설정하라.
2. 부산의 기온 데이터 분석하기
# CSV 파일에서 데이터 읽어오기
CSV파일을 읽어오는 과정은 4단계로 나뉜다.
- 1. CSV 라이브러리 불러오기
- 2. CSV 파일 열기
- 3. 데이터를 컴마(,)로 구분하여 저장하기
- 4. for로 한줄씩 꺼내기
이제 CSV파일에서 데이터를 읽어볼텐데 그전에 데이터를 처리하기 쉽게 다음과 같은 부분을 삭제한다.

다음과 같이 바꾸고 pusan.csv로 다른이름으로 저장한다.

# 주피터 실행하기
아나콘다를 설치하면 주피터 노트북이 함께 설치된다. 주피터 노트북을 실행한다.
실행하면 이런 검은 화면이 나오고 10초내에 브라우저가 열린다.
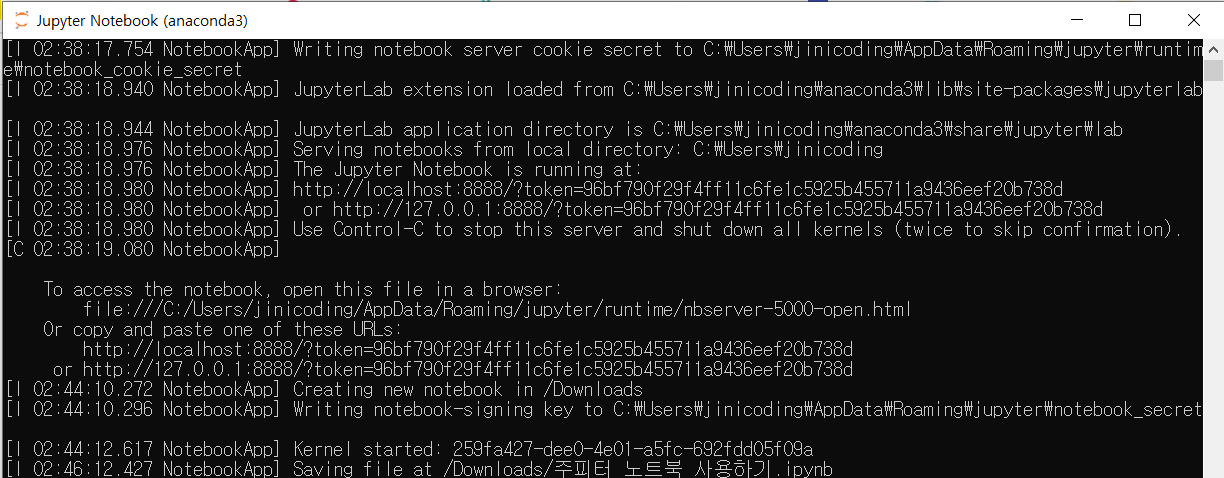

이것은 본인의 컴퓨터이다. 여기서 우리는 CSV파일이 있는 곳으로 가서 주피터 노트북을 시작한다.

# CSV파일에서 데이터 읽어오기
- 1. CSV 라이브러리 불러오기
- 2. CSV 파일 열기
- 3. 데이터를 컴마(,)로 구분하여 저장하기
- 4. for로 한줄씩 꺼내기
CSV파일을 읽어오는 4가지 단계를 그대로 따라치자.
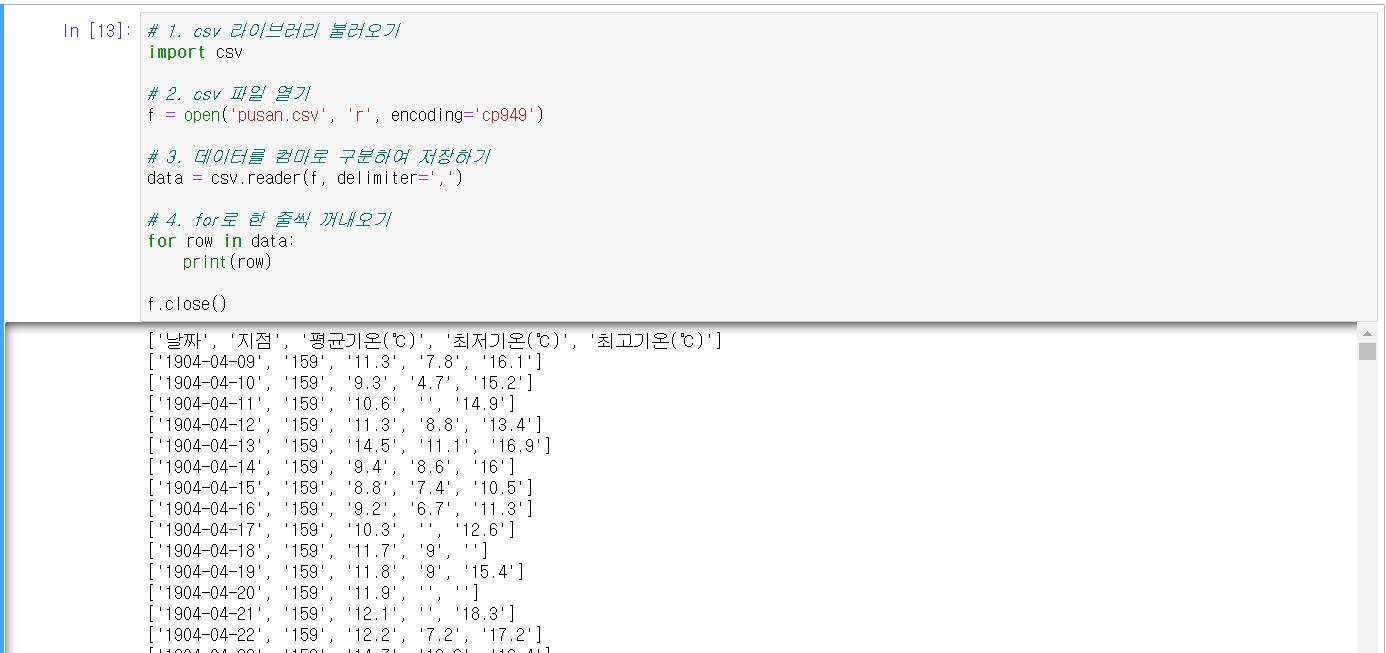
1. csv 모듈을 불러온다.
import csv
2. csv 파일을 open()함수로 열어서 파일 객체 f에 저장한다.
f = open('pusan.csv', 'r', encoding='cp949')'r'은 읽기모드를 뜻하고, 'cp949'는 windows 한글 인코딩 방식이다.
3. f를 reader()함수에 넣어 data라는 csv reader 객체를 생성한다.
data = csv.reader(f, delimiter=',')delimiter=','은 해당 데이터를 ,로 구분해서 저장하겠다는 뜻이다.
4. for문으로 한 줄(row)씩 가져와서 출력한다.
for row in data:
print(row)
5. 파일 닫기
f.close()

여기서 데이터는 []로 둘러싸여있는 것을 통해서 우리는 row가 리스트라는 것을 알 수 있다. 이것은 인덱싱과 슬라이싱을 할 수 있다는 것이다.
# 헤더 저장하기
헤더(header)는 데이터 파일에서 여러가지 값들이 어떤 의미를 갖는지 표시한 행을 말한다. 헤더는 데이터의 첫번째 줄의 위치한다.

next() 함수는 첫번째 데이터 행을 읽어오면서 데이터의 탐색 위치를 다음 행으로 이동시킨다.
그러면 header에 헤더를 저장하고 데이터들을 출력해보자.
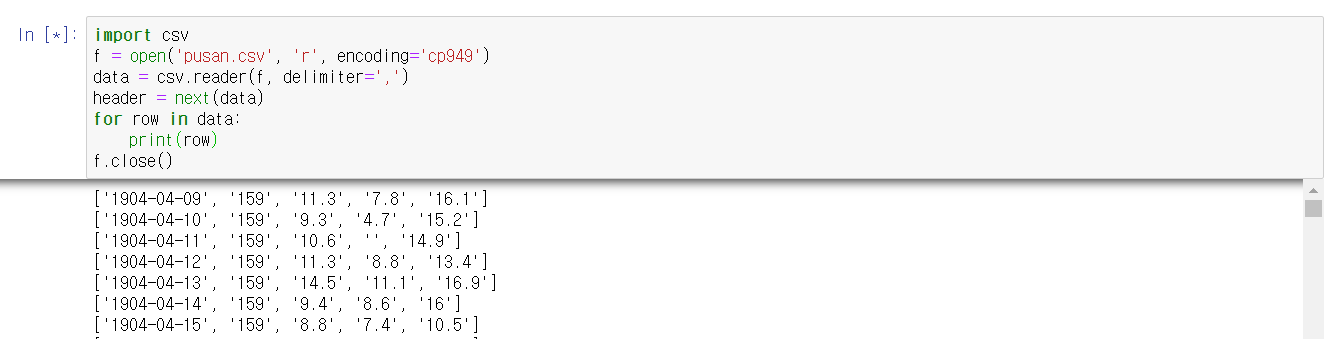
첫번째 행이 출력되지않고, 다음(next)행인 두번째 행부터 출력되는 것을 확인할 수 있다.
3. 부산이 가장 더웠던 날은 언제였을까?
# 질문 다듬기
기상 관측 아래, 부산의 최고기온이 가장 높았던 날은 언제였고, 몇 도였을까?
필요한 데이터 => 최고기온, 날짜
# 문제 해결방법 구상하기
- 1. 데이터를 읽어온다.
- 2. 순차적으로 최고기온을 확인한다.
- 3. 최고 기온이 가장 높았던 날짜의 데이터를 저장한다.
- 4. 최종 저장된 데이터를 출력한다.
# 파이썬 코드로 구현하기
현재 데이터들은 str(문자열 데이터)로 저장되어 있기 때문에 이것을 실수(float)으로 변환할 필요가 있다.
import csv
f = open('pusan.csv')
data = csv.reader(f)
header = next(data)
for row in data:
row[-1] = float(row[-1])
print(row)
f.close()row의 마지막 index(-1) 데이터를 float()으로 형변환하여 저장한다.

다음과 같은 에러를 발생한다.
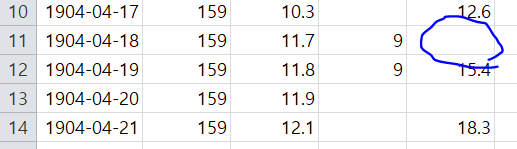
데이터는 인간의 실수, 혹은 어떠한 이유로 인해서 누락되거나 오류가 있는 데이터가 존재할 수 있기 때문이다. 따라서 우리는 이것을 체크해줘야한다.
import csv
f = open('pusan.csv')
data = csv.reader(f)
header = next(data)
for row in data:
if row[-1] == '': # 데이터가 누락되었다면
row[-1] = -999 # 최고기온으로 불가능한 값인 -999를 저장한다.
row[-1] = float(row[-1])
print(row)
f.close()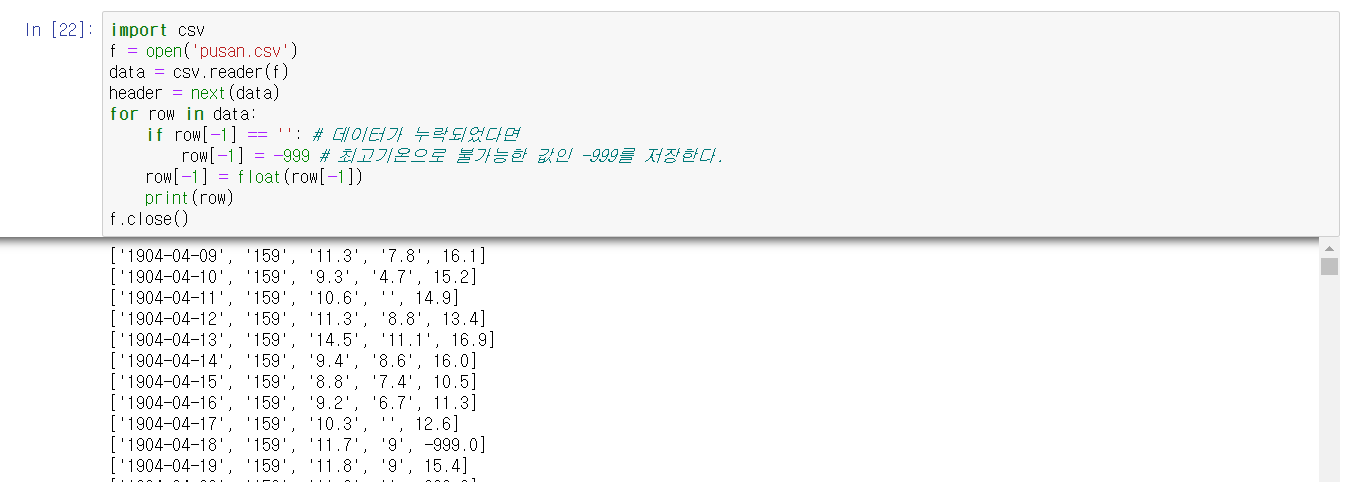
데이터가 정확히 저장되었다. 이제 최고기온을 비교하여 최고기온을 저장한다.
# 최고기온 구하기
import csv
f = open('pusan.csv')
data = csv.reader(f)
header = next(data)
max_temp = -999
max_date = ''
for row in data:
if row[-1] == '':
row[-1] = -999
row[-1] = float(row[-1])
if row[-1] > max_temp:
max_temp = row[-1]
max_date = row[0]
print('기상 관측 이래 부산의 최고 기온이 가장 높았던 날은 {}로, {}도 였습니다.'.format(max_date, max_temp))
f.close()
실제로 기사로 찾아보니깐 맞군요.
참고로 출력문구를 다음과 같이하면 연산속도를 더 빠르게 할 수 있습니다.
print(f'기상 관측 이래 부산의 최고 기온이 가장 높았던 날은 {max_date}로, {max_temp}도 였습니다.')
'PNU DSC > 파이썬 데이터 분석' 카테고리의 다른 글
| 03-2. 인구 공공데이터2 (0) | 2020.05.15 |
|---|---|
| 03-1. 인구 공공데이터 1 (0) | 2020.05.11 |
| 02-3. 데이터 시각화 기초 3 (1) | 2020.05.06 |
| 02-2. 데이터 시각화 기초 2 (0) | 2020.05.05 |
| 02-1. 데이터 시각화 기초 1 (1) | 2020.05.05 |